The goal of this project is to use the geoprocessing skills I have acquired from tutorials and lectures to answer a spatial question of my choosing. The study area that is the focus of
this project is Eau Claire County which is located in the state of Wisconsin.
The question I have proposed for this project is where are suitable locations
for deer ticks to survive within Eau Claire County, with restrictions to
certain vegetation types and locations of forests. Deer ticks primarily thrive
in wooded areas and areas of low-lying vegetation. This eliminates any areas
that do not meet those criteria, including urban areas and along roads, where I
have set a perimeter of 500 meters from any major road. The intended audience
for this map is anyone who lives in Eau Claire County, this information could
be used by the Wisconsin DNR and is important because deer ticks are the only
known possible carriers of Lyme Disease and knowing the areas in which deer
ticks can survive is helpful in preventing people from contracting Lyme
Disease.
Methodology
I used data from a few different places. The first being the WI DNR dataset made available to me through the UW-Eau Claire Geography Department. The data I got from this dataset is the Eau Claire County outline, vegetation cover and county forest feature classes and the major roads feature class. The second place I obtained data from is the Geospatial Data Gateway through their website at http://datagateway.nrcs.usda.gov/GDOrder.apsx, from this website I obtained the urban areas feature class. The final source for my data came from accessing ArcGIS online. After a brief search for Wisconsin water bodies, I found a suitable layer that I clipped to fit to Eau Claire County. With my data being from multiple different sources a concern I have for my data is that not all of the data corresponds with each other in terms of accuracy in location. For example, the urban areas feature class may be in a different location if it were from the same dataset as the major roads feature class. In a way this reflects my concern with using data from multiple different sources.
To create the map for suitable deer tick habitats I started by connecting to the WIDNR2014 geodatabase. From this database I obtained the Wisconsin counties feature class, the Wisconsin major roads feature class, the Wisconsin county forests feature class and the Wisconsin original vegetation cover feature class. In order to be able to see the county boundaries beneath the other layers, I changed the transparency of the vegetation cover feature class to 50% for the time being. My area of interest was Eau Claire County, so I used the select by attributes tool to highlight Eau Claire, the query I used was COUNTY_NAM = ‘Eau Claire’, then I simply created a layer from the selected features and named it “Eau_Claire_Co”. I also needed to select the appropriate vegetation that deer ticks could live in; since deer ticks thrive primarily in wooded areas and low-lying vegetation, I needed to find areas where low-lying vegetation were in Eau Claire County. I searched Google to find information on the vegetation cover feature class I was using in my map and found the values that corresponded with low-lying vegetation to be scrub, prairie and brush. The values that represent these three vegetation types are 6, 12, and 13. So I again used the select by attributes tool to highlight these attributes. The query I used was VEG_TYPE = ‘6’ OR VEG_TYPE = ‘12’ OR VEG_TYPE = ‘13’. I also created a new layer from these selected features to use as the vegetation cover on my map and named it “DeerTickVeg”.
With my study area being Eau Claire County, it was obvious I needed to narrow down each feature class I was using so that each was contained within the borders of the Eau Claire County feature class. The first few feature classes I clipped were the major road feature class, the DeerTickVeg feature class, and the county forest feature class. Now I had all my feature classes contained within my area of interest, but I figured I needed more for this project than I had. So I downloaded data from Geospatial Data Gateway at their website http://datagateway.nrcs.usda.gov/GDGOrder.aspx, selected my state as Wisconsin and the county as Eau Claire county, and found that the Urban Areas of Wisconsin dataset was something that could be included in my map. I then downloaded the data and added the urban areas feature class to my map. However, the urban areas feature class was not specific to Eau Claire county, so I used the clip tool again to make it specific to only Eau Claire county. I also added data from ArcGIS online. This data was the Topper_Wisconsin_Water_bodies_Service layer and I added it to my map and clipped it to Eau Claire county to get the water bodies that are contained in my study area.
Deer ticks can live in both wooded areas and areas of low-lying vegetation. This meant that I needed to combine the DeerTickVeg feature class and the county forests feature class, and to do so I used the union tool in order to keep all features of both feature classes, not just what was common to both. I named the new feature “deertick_forestveg”. Also, in order to get rid of any boundaries within the feature class, I used the dissolve tool to make it one complete, smooth feature. This indicates on my map that deer ticks can survive in either wooded areas or areas of low-lying vegetation. Next I used the clip tool on the major roads feature class to get major roads contained in the deertick_forestveg feature class. I did this because the roads within the deertick_forestveg feature class represent an unsuitable area for any deer tick habitat. I named the new feature class “deertick_majroads”, then used the buffer tool and gave it a boundary of 500 meters and named the feature class that came from the tool “DT_MRbuff”. Then to get rid of any unwanted boundaries within the buffered feature class I used the dissolve tool and named the feature class that came from it “DT_MRdissolve”. The feature class had buffers that extended outside the Eau Claire county border so to get rid of those I clipped the DT_MRdissolve feature class and named the new feature class “DT_MRclip”. Then I intersected this feature class with the deertick_forestveg feature class. The final step in completing my map was to eliminate any unsuitable areas from the urban area in Eau Claire county. This involved the using the erase tool to get rid of any parts of the DT_MRclip feature class that were contained in the urban areas feature class, and the dissolve tool to get rid of any unwanted boundaries.
One extra step I took in creating a map of potential deer tick habitats was projecting the map in a projection I deemed appropriate for my study area. Eau Claire county is within the central zone of the state of Wisconsin, so the projection I chose for my map was NAD_1983_StatePlane_ Wisconsin_Central_FIPS_4802 and I applied this projection to each layer that was on my map.
To create the map for suitable deer tick habitats I started by connecting to the WIDNR2014 geodatabase. From this database I obtained the Wisconsin counties feature class, the Wisconsin major roads feature class, the Wisconsin county forests feature class and the Wisconsin original vegetation cover feature class. In order to be able to see the county boundaries beneath the other layers, I changed the transparency of the vegetation cover feature class to 50% for the time being. My area of interest was Eau Claire County, so I used the select by attributes tool to highlight Eau Claire, the query I used was COUNTY_NAM = ‘Eau Claire’, then I simply created a layer from the selected features and named it “Eau_Claire_Co”. I also needed to select the appropriate vegetation that deer ticks could live in; since deer ticks thrive primarily in wooded areas and low-lying vegetation, I needed to find areas where low-lying vegetation were in Eau Claire County. I searched Google to find information on the vegetation cover feature class I was using in my map and found the values that corresponded with low-lying vegetation to be scrub, prairie and brush. The values that represent these three vegetation types are 6, 12, and 13. So I again used the select by attributes tool to highlight these attributes. The query I used was VEG_TYPE = ‘6’ OR VEG_TYPE = ‘12’ OR VEG_TYPE = ‘13’. I also created a new layer from these selected features to use as the vegetation cover on my map and named it “DeerTickVeg”.
With my study area being Eau Claire County, it was obvious I needed to narrow down each feature class I was using so that each was contained within the borders of the Eau Claire County feature class. The first few feature classes I clipped were the major road feature class, the DeerTickVeg feature class, and the county forest feature class. Now I had all my feature classes contained within my area of interest, but I figured I needed more for this project than I had. So I downloaded data from Geospatial Data Gateway at their website http://datagateway.nrcs.usda.gov/GDGOrder.aspx, selected my state as Wisconsin and the county as Eau Claire county, and found that the Urban Areas of Wisconsin dataset was something that could be included in my map. I then downloaded the data and added the urban areas feature class to my map. However, the urban areas feature class was not specific to Eau Claire county, so I used the clip tool again to make it specific to only Eau Claire county. I also added data from ArcGIS online. This data was the Topper_Wisconsin_Water_bodies_Service layer and I added it to my map and clipped it to Eau Claire county to get the water bodies that are contained in my study area.
Deer ticks can live in both wooded areas and areas of low-lying vegetation. This meant that I needed to combine the DeerTickVeg feature class and the county forests feature class, and to do so I used the union tool in order to keep all features of both feature classes, not just what was common to both. I named the new feature “deertick_forestveg”. Also, in order to get rid of any boundaries within the feature class, I used the dissolve tool to make it one complete, smooth feature. This indicates on my map that deer ticks can survive in either wooded areas or areas of low-lying vegetation. Next I used the clip tool on the major roads feature class to get major roads contained in the deertick_forestveg feature class. I did this because the roads within the deertick_forestveg feature class represent an unsuitable area for any deer tick habitat. I named the new feature class “deertick_majroads”, then used the buffer tool and gave it a boundary of 500 meters and named the feature class that came from the tool “DT_MRbuff”. Then to get rid of any unwanted boundaries within the buffered feature class I used the dissolve tool and named the feature class that came from it “DT_MRdissolve”. The feature class had buffers that extended outside the Eau Claire county border so to get rid of those I clipped the DT_MRdissolve feature class and named the new feature class “DT_MRclip”. Then I intersected this feature class with the deertick_forestveg feature class. The final step in completing my map was to eliminate any unsuitable areas from the urban area in Eau Claire county. This involved the using the erase tool to get rid of any parts of the DT_MRclip feature class that were contained in the urban areas feature class, and the dissolve tool to get rid of any unwanted boundaries.
One extra step I took in creating a map of potential deer tick habitats was projecting the map in a projection I deemed appropriate for my study area. Eau Claire county is within the central zone of the state of Wisconsin, so the projection I chose for my map was NAD_1983_StatePlane_ Wisconsin_Central_FIPS_4802 and I applied this projection to each layer that was on my map.
 |
Figure 1: Final Map

Figure 2: Work Flow Model
Results
The
results of all of the data and tools used to complete my project is a map that
shows potential areas suitable for deer tick habitat shown in green, areas that
are not suited for deer tick to survive along the major roads in Eau Claire
county, shown in orange and urban areas in Eau Claire county that would also be
unsuitable for deer tick habitat shown in a salmon pink color. Streams, shown
in blue lines on the map as well as Eau Claire county, shown in a light tan
color serve as a backdrop to the features on the map. In layout view I created
two other data frames to go along with the one containing my finished map
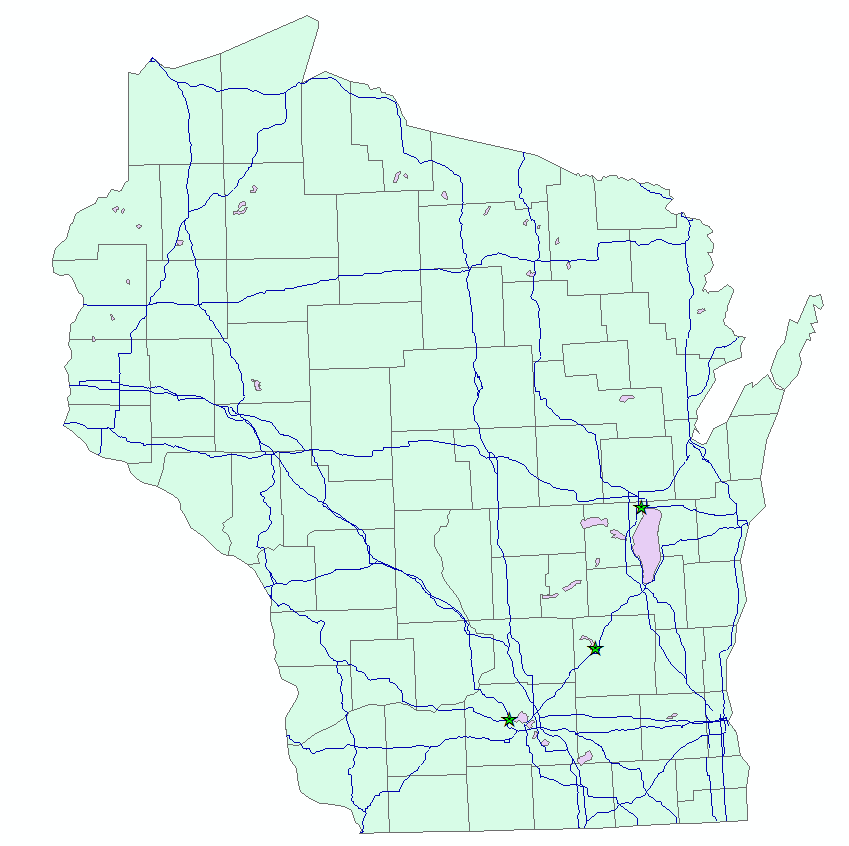
(Figure 1). The second data frame contains a locator map that shows where my
study area is located in the state of Wisconsin (Figure 3). The third data
frame contains the data flow model I generated in ArcMap that shows the steps I
took to complete my project. (Figure 2). The
final product with all the data frames combined is shown in Figure 4 below.

Figure 3: Locator Map

Figure 4: Final Map Layout
|